 ioProgrammo N°9, Novembre 1997 ©Copyright DIEMME Editori
ioProgrammo N°9, Novembre 1997 ©Copyright DIEMME Editori
ioProgrammo N°9, Novembre 1997 ©Copyright DIEMME Editori

#!/usr/bin/perl
require "cgi-lib.pl";
$host = "http://localhost/";
$search_dir = "/home/httpd/html/";
@url_dir = ('', 'www/');
chdir($search_dir);
foreach $dir (@url_dir) {
push(@file, `ls $dir*.htm*`);
}
&ReadParse(*CGI);
&HTML;
&Cerca;
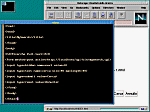 si richiama la libreria cgi-lib.pl con la consueta funzione require e poi si impostano alcune variabili scalari.
$host è l'URL del nostro server, $search_dir contiene il path assoluto della directory in cui sono contenuti tutti i documenti html pubblici (la DocumentRoot nel file httpd.conf del server Apache). Poi abbiamo l'array @url_dir, inizializzato con le sottodirectory pubbliche del server web e che servirà per costruire i link con i tag <A HREF> restituiti dalla ricerca.
si richiama la libreria cgi-lib.pl con la consueta funzione require e poi si impostano alcune variabili scalari.
$host è l'URL del nostro server, $search_dir contiene il path assoluto della directory in cui sono contenuti tutti i documenti html pubblici (la DocumentRoot nel file httpd.conf del server Apache). Poi abbiamo l'array @url_dir, inizializzato con le sottodirectory pubbliche del server web e che servirà per costruire i link con i tag <A HREF> restituiti dalla ricerca.
Ovviamente tali variabili possono essere adattate alla particolare configurazione del server senza modificare altre parti del programma. La funzione chdir, predefinita in Perl, cambia la directory di lavoro da /home/httpd/cgi-bin/ a /home/httpd/html, e per ogni sottodirectory web si "riempie" l'array @file con la funzione push tramite la chiamata di sistema ls che restituisce la lista di tutti i file htm o html su cui si farà la ricerca. Sulla funzione &HTML
sub HTML {
print "Content-type: text/html\n\n";
print "<HTML>\n<HEAD>\n<TITLE>Risultati della ricerca</TITLE>\n</HEAD>\n";
print "<BODY bgcolor=#ffffff>\n";
print "<H3>Risultati della ricerca</H3>\n";
}
non c'è molto da dire. In sostanza apre l'output di tag html per costruire la pagina di risposta alla nostra interrogazione.
Tutti i motori di ricerca che si rispettino, offrono la possibilità di ottenere una paginazione dei link restituiti.
Yahoo ed Altavista fanno da esempio. In pratica, poiché è molto scomodo e poco efficiente ottenere una valanga di tag <A HREF> con rispettiva descrizione, conviene sospendere l'elenco restituito per poi riprenderlo cliccando sul consueto pulsante a piè di pagina. All'utente verrà da un lato risparmiata l'attesa della fine della ricerca e dall'altro gli si premette di scegliere tra il proseguire con l'elenco o l'eseguire una nuova ricerca.
Il numero di link per pagina può essere impostato sullo stesso form usato per immettere la parola chiave
oppure direttamente nel programma. Tra le due opzioni noi sceglieremo la seconda, lasciando la prima a quanti vorranno fare esercizio con Perl.
sub Next {
local($next, $cerca) = @_;
print "<form method=post action=http://localhost/cgi-bin/mysearch.cgi>";
print "<input type=hidden name=next value=$next>";
print "<input type=hidden name=cerca value=$cerca>";
print "<input type=submit name=nextbutton value=Altri...>";
print "</form>\n";
}
sub Next è una funzione un po' particolare. Innanzi tutto riceve due parametri, passaggio effettuato con una chiamata all'interno della subroutine &Cerca, e poi prepara un form html (il pulsante per la paginazione) in cui compaiono ben due campi di input nascosti.
Cliccando sul pulsante Altri..., non si fa altro che passare allo script search.cgi il contenuto delle variabili $next e $cerca, rispettivamente il numero di file processati dall'algoritmo di ricerca e la parola chiave da trovare. La stampa dei link verrà poi ripresa se i documenti rimanenti soddisfano i criteri di interrogazione.
Anche Form è molto semplice. Viene usata per poter fare una nuova ricerca alla fine di ogni schermata di link, evitando l'uso ripetuto del pulsante "Back" di Netscape per ritornare al form di partenza.
sub Form {
print "<form method=post action=http://localhost/cgi-bin/mysearch.cgi>";
print "<input type=hidden name=next value=0>";
print "<input type=text name=cerca size=40 maxlength=40>";
print "<input type=submit value=Cerca>";
print "<input type=reset value=Annulla>";
print "</form>";
print "</body>";
print "</html>\n";
}
Si noti la presenza di un campo nascosto, usato per azzerare il numero di file processati e poter quindi eseguire una ricerca sul totale dei documenti html.
Ed ora inizia il bello.
Siamo finalmente arrivati alla subroutine Cerca. Non spaventiamoci perché anche questa funzione non è affatto complicata. Grazie alla potenza delle espressioni regolari di Perl, potremo fare ricerche full-text scrivendo in pratica solo due righe di codice: provate con il C/C++ e buona fortuna con i puntatori.
Poiché il risultato della nostra ricerca sarà un elenco di titoli di pagine html e rispettivo url, il metodo migliore per presentarlo consiste nell'uso delle liste puntate con i tag <UL>/<LI>. Inizializziamo subito la variabile $link per tale compito.
Poi ci servono due contatori, $i e $k. Il primo avrà valore massimo pari al numero di link per pagina che si vorrà restituire; il secondo memorizza il numero di documenti interrogati.
sub Cerca {
$link = "<UL>\n";
$i = 0; $k = 0;
foreach $file (@file) {
open (FILE, "$search_dir$file");
while (<FILE>) {
if ($_ =~ /<title>(.*)<\/title>/i) {
$title = "$1";
}
else {
$title = $file;
}
if ($_ =~ /$CGI{'cerca'}/i) {
if ($k > $CGI{'next'}) {
$trovato = "yes";
$link .= "<LI><A HREF=$host$file>$title</A><BR>\n";
$link .= "<I>$host$file</I>\n</LI><P>\n";
$i++;
last;
}
}
}
close(FILE);
$k++;
if ($i == 3) {
last;
}
}
if (! $trovato) {
print "\"<B>$CGI{'cerca'}\"</B> non trovato\n";
}
else {
print "$link</UL>\n";
}
if ($i == 3) {
&Next($k-1, $CGI{'cerca'});
}
&Form;
}
 Il ciclo foreach consente di aprire ogni file html dell'array @file, estrarne il titolo e verificare se il file contiene la stringa o sottostringa cercata.
Il titolo viene memorizzato nella variabile speciale $1. In Perl questa variabile è il contenuto delle parentesi dell'espressione regolare /<title>(.*)<\/title>/i. Questa "regular expression" dice in pratica di riscontrare qualsiasi sequenza di caratteri, eccetto il new-line, racchiusa tra i tag <TITLE> e </TITLE>.
Il ciclo foreach consente di aprire ogni file html dell'array @file, estrarne il titolo e verificare se il file contiene la stringa o sottostringa cercata.
Il titolo viene memorizzato nella variabile speciale $1. In Perl questa variabile è il contenuto delle parentesi dell'espressione regolare /<title>(.*)<\/title>/i. Questa "regular expression" dice in pratica di riscontrare qualsiasi sequenza di caratteri, eccetto il new-line, racchiusa tra i tag <TITLE> e </TITLE>.
Siamo quindi sicuri che tale sequenza è proprio il titolo del file html. Se però il riscontro non dovesse avere successo, il titolo sarà il nome del file. Successivamente con /$CGI{'cerca'}/i si riscontra la parola cercata e poi si verificano ed incrementano i contatori. Infine una ulteriore serie di confronti stabilirà se il risultato della ricerca potrà essere stampato oppure permettere una nuova interrogazione se invece la ricerca dovesse fallire. Abbiamo veramente concluso. Questa rassegna di articoli sul Perl e lo scripting CGI termina qui. Si potrebbero scrivere ancora molte pagine ma è giusto lasciare spazio a nuove idee e nuovi argomenti. Le nuove tecnologie per lo sviluppo su Internet richiedono macchine sempre più potenti e software affamati di risorse. Linux e il suo kit di strumenti di programmazione non deve temere i giganti come Microsoft e Lotus poiché rappresenta un sistema eccezionale per programmare a basso costo ma con facilità ed efficacia. Nel frattempo buona ricerca a tutti.
Data creazione HTML: Febbraio 1998
Autore: Francesco Munaretto
E-mail: NoSpam@thank.you
